
For my first open source release of code, I bring you an Android Compound Control. This particular custom control is a number picker with a repeat feature. This is a very basic control, but not one that is provided in the given pre-built control set. For those of you looking to easily fill that void, or perhaps learn how the auto-increment feature was implemented, I give you NumberPicker.
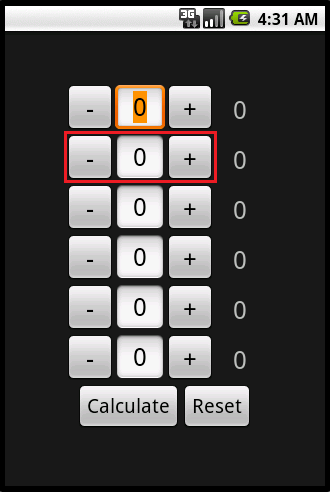
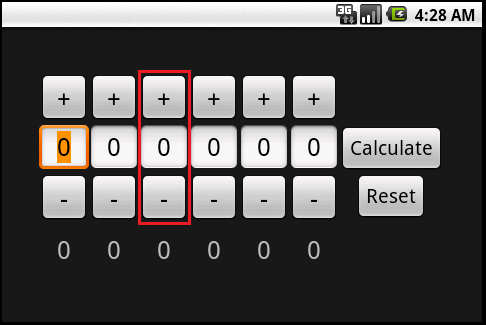
NumberPicker is an extension of LinearyLayout, and as such can be configured horizontally or vertically, shown above. The size of the elements is hard coded at this time, but by looking in the documentation it can be seen that it is very easily changed. Here is an example of using a vertically configured version of this element in an XML layout:
<net.technologichron.android.control.NumberPicker
android:id="@+id/Picker1"
android:orientation="vertical"
android:layout_width="wrap_content"
android:layout_height="wrap_content">
</net.technologichron.android.control.NumberPicker>
There are two particular elements of this control I’d like to talk about. Firstly, is implementing the repeat feature. My first instinct when developing this was to spawn a thread to periodically change the value as long as a user held one of the buttons. I quickly learned that this wasn’t possible by simply spawning a Thread, as only the GUI thread can make changes to the GUI. Further reading in the Android manual led me to the use of Handler to schedule the changes.
Whenever a button is long pressed, a flag is set, and a new Runnable, RepetetiveUpdater, is posted to the Handler. This new RepetetiveUpdater will check if a flag is set, and increment or decrement the value appropriately, and then post a new RepetetiveUpdater to the Handler with a delay of 50 ms. Once the user releases the button, an OnTouchListener checks if the the last touch action was the release of the active button and disables the flag originally set when the long click first occurred.
The second thing I’d like to point out is how the parsing occurs for the EditText value from String to Integer. Much to my surprised, one utilizing a hardware keyboard can force non-numeric characters into an EditText that is configured to be numeric.
There are two issues with this; we don’t want to crash trying to parse something that’s not an Integer, and we don’t want to have our number go up and away if a new line gets through. To mitigate these issues, whenever a key is pressed, an OnKeyListener will save the current valid value that was in place before the user pressed a key, attempt to parse the new text as is, and if it fails, restore the edit text to the last valid value. In this way, whenever a invalid key is pressed, the user doesn’t even notice.
I hope that there will be some utility to some one by me releasing NumberPicker under the BSD license. If you have any questions feel free to voice them in the Comments.
UPDATE: I’ve created a sample Eclipse project that may help you work out implementation details: NumberPickerExample
Hi Jeffrey,
This is sooo what im looking for right now. The Illusive Stepper! Do you by chance have a sample app
with your NumberPicker Class included so as I can see it working in an attempt to adapt it
for an Android calculator I messing with. I cant quite work out how to implement your XML
struct above.
Regards,
Adrian
@Adrian Firstly, I’m glad to see that you’re interesting in using my code. Secondly, I put together a test project to make sure I could implement this from scratch and I realized two errors in the XML I provided.
One being that I referenced a style I did not provide, and the second being the tag wasn’t closed. Silly me! I’ve update the post to reflect these corrections.
Also, you can download the example Eclipse project I created NumberPickerExample
Thanks, its simple and works excellent
Go open source.
Regards,
Acker
Thanks for the useful code, slight update you might want to make however is the initial integer should really be the minimum value and not a presumed 0.
-Ian
good work ,
thanks
@Ian I disagree. In the cases where I’ve used it, all of the picker values were used in a formula, where having a zero values would not affect the formula. If it were implemented as you describe, one would have to explicitly reset all the pickers to zero for them to not affect the formula. In this case, I consider that poor usability. However, being as you have access to the source code, you could easily implement that change yourself in whichever situation you feel that functionality is appropriate.
@Admin In that case it would be nice to have a method which allowed placing a true minimum to the display. I of course already did this on my side with the minimum usage as for my use a value of 0 can not be permitted. Just a usability suggestion.
Thanks again for the code, it was a huge time saver on something that really should be part of the main android library :shakes fist at Google:
@Ian I would really have liked to setup some custom attributes definable in the XML layout, such as the min, max, and initial value. Any reset method then would just set it back to its initial value. If I find the time I may set about doing that, but for this release I was just hoping to get my first piece of public code out the door for those needing it.
And you’re very welcome! The greatest reward is knowing that people are actually finding this useful.
Hi. Just want to say thanks for releasing something genuinely useful and easy to deconstruct/learn.
I’m relatively new to Java, I am writing my first Android application and stumbled upon this page. lets say I want this to be user input for a integer, I have the code inside of my app so it makes the numberpicker but how do I compare it using say a if statement to compare it to a integer?
would it be possible to add something like an onChangeListener?
So i could update some calculated values as soon as someone changes the NumberPicker’s value.
Would be great 🙂
Hey there,
thanks for your work, this is really useful.
Smart ass annotation, line 100 or so should read:
LayoutParams elementParams = new LinearLayout.LayoutParams( ELEMENT_WIDTH, ELEMENT_HEIGHT);
You reversed width and height but that, of course, doesn’t matter if using squares.
Thx again!
Thank you for creating this component. It is the best and most lightweight solution to the problem I’ve seen!
I added the following to the NumberPicker, and thought it would be useful to feed this back:
public void setEnabled(boolean enabled) {
this.enabled = enabled;
valueText.setEnabled(enabled);
decrement.setEnabled(enabled);
increment.setEnabled(enabled);
}
public boolean isEnabled() {
return enabled;
}
Can you tell me how do i get the values from your picker, and i want to set values on it.
for exemple i select an object from a database, for exemple percentage done, and i want to edit it so the beggining number on the picker as to be X(the percentage)
and btw great job, simple way to create, no bugs works fine, i just need to know this and will be perfect
That’s what I was looking for, thanks man. By the way, very clean code, congrats. 🙂
Cheers.
Hi,
thanx for this code!
I have a question. If I want to get number value from another java file, how can I do this? How to get number value which is selected?
Thank for your help!
Hi Jeffrey,
Thanks for publishing this. Even in Android 2.3, I believe we are still lacking a first party control in the SDK to do this…! Your contribution really helped me out, so thank you!
I made some minor tweaks:
* Corrected the Length and Width assignment (Quelltextfabrik)
* Gave the buttons a different width than the value box
* Set the initial value to MINIMUM (Ian)
Regards,
Timothy.
Sir, I am having problem using intent with your java file.What i am trying is loading an initial screen on click will lead to the number picker.Would appreciate alot if you take some time to reply me.
thanking you
siddhartha
Thx for the script! 🙂
But plz write how to use it for Java noobs like me.
For noobs like me:
but the NumberPicker.java file in your src/***/ folder.
For me it is src/com.android.GissaSiffran
edit package net.technologichron.manacalc to your own package name.
For me it is com.android.GissaSiffran.
In your XML file, in a tag paste the XML code (u find it in the post).
Edit net.technologichron.android.control.NumberPicker to your own package name.
For me it is com.android.GissaSiffran.NumberPicker.
Thank you for this. Exactly what I needed.
Thanks for sharing, this solution is of great help.
Although there seems to be a problem with soft keyboards and the onKeyListener, so I replaced it with a TextWatcher as found on http://www.inadaydevelopment.com/?p=286 (along with some other minor tweaks – the setValue() method justs acts as a setter for the value and additionally sets the value of the EditText element so that they are always consistent):
valueText.addTextChangedListener(new TextWatcher() {
private int backupValue;
@Override
public void beforeTextChanged(CharSequence s, int start, int count, int after) {
backupValue = value;
}
@Override
public void onTextChanged(CharSequence s, int start, int before, int count) { }
@Override
public void afterTextChanged(Editable s) {
String string = s.toString().trim();
if(string.equals("")) {
setValue(1);
return;
}
try {
value = Integer.parseInt(s.toString());
if(value > MAXIMUM) {
setValue(MAXIMUM);
}
} catch( NumberFormatException nfe ){
setValue(backupValue);
}
}
});
Thanks! The simple control I needed.
Thanks A 1.000.000 for this.
Very best and easy, eaven for noob as me.
+1 +1 +1 +1 !
Wau, thanks for the code. Nice work!!! You save a lot of my time.
How create this object in programmatically ?
AttributeSet MyAttributeSet = ;
new NumberPicker(this, MyAttributeSet);
How do you retrieve the value of the edittext from an activity? That seems to be the final piece to this puzzle. Thank you
@Max Here is how you retrieve the value of the edittext:
I have a NumberPicker called Picker1 and a TextView called mytv in my main.xml
This will set the Textview to the current NumberPicker Number:
NumberPicker mynp = (NumberPicker)findViewById(R.id.Picker1);
int currentNumber = mynp.getValue();
TextView tv = (TextView)findViewById(R.id.mytv);
tv.setText(Integer.toString(currentNumber));
Full code (just test project so excuse any unprettiness … and I only add the switch cause I’m about to extend the project:
package com.friendlysanj.numberpickersanj;
import android.app.Activity;
import android.content.Context;
import android.os.Bundle;
import android.view.View;
import android.view.View.OnClickListener;
import android.widget.Button;
import android.widget.TextView;
import android.widget.Toast;
import com.friendlysanj.numberpickersanj.NumberPicker;
public class NumberPickerSanjActivity extends Activity {
Button getButton;
/** Called when the activity is first created. */
@Override
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.main);
Button getButton = (Button)findViewById(R.id.get);
getButton.setOnClickListener(mAddListener);
}
// Create an anonymous implementation of OnClickListener
private OnClickListener mAddListener = new OnClickListener()
{
public void onClick(View v)
{
switch(v.getId())
{
case R.id.get:
try
{
NumberPicker mynp = (NumberPicker)findViewById(R.id.Picker1);
int currentNumber = mynp.getValue();
TextView tv = (TextView)findViewById(R.id.mytv);
tv.setText(Integer.toString(currentNumber));
}
catch (Exception ex)
{
Context context = getApplicationContext();
String text = ex.toString();
int duration = Toast.LENGTH_SHORT;
Toast toast = Toast.makeText(context, text, duration);
toast.show();
}
break;
}
}
};
}
Here’s a cool post which tells you how to implement a listener to your custom control:
http://www.geekmind.net/2010/10/android-implementing-your-own-listener.html
Here is how I did it for this control:
Again, just test, so not prettified:
Under the setvalue method, add this lot:
public void setValue( int value ){
if( value > MAXIMUM ) value = MAXIMUM;
if( value >= 0 ){
this.value = value;
valueText.setText( this.value.toString() );
}
}
protected OnNumberPickerChangedListener mOnNumberPickerChangedListener;
public interface OnNumberPickerChangedListener {
void onNumberPickerChanged(NumberPicker mynumberpicker);
}
/**@param 1 – the new change listener */
public void setOnNumberPickerChangedListener(OnNumberPickerChangedListener l) {
this.mOnNumberPickerChangedListener = l;
}
private void notifyListener() {
if (this.mOnNumberPickerChangedListener != null) {
this.mOnNumberPickerChangedListener.onNumberPickerChanged(this);
}
}
Modify Increment and Decrement to call the notifyListener:
public void increment(){
if( value MINIMUM ){
value = value – 1;
valueText.setText( value.toString() );
notifyListener();
}
}
and in your activity, add this in the OnCreate (I am just displaying the number + 2 in a textview called mytv2):
NumberPicker mynp = (NumberPicker)findViewById(R.id.Picker1);
mynp.setOnNumberPickerChangedListener(new NumberPicker.OnNumberPickerChangedListener() {
@Override
public void onNumberPickerChanged(NumberPicker mynp) {
// TODO Auto-generated method stub
int currentNumber = mynp.getValue() + 2;
TextView tv2 = (TextView)findViewById(R.id.mytv2);
tv2.setText(Integer.toString(currentNumber));
}
});
BTW – Jeff – thanks for the great control and code.
How can i restrict users to edit the numbers. How can i Block the text entry and it should be doable only using the + and –
Thanks, my friend, for this amazingly easy methodology. I was stuck for recent few days due to non-flexibility of DatePicker, now I could easily replace it with my own date picker using your code. Thanks and thanks again 🙂
NumberPicker.java link is down
Sorry about that. All fixed now.
Hello, I use your number picker.
On Samsung s3 the + and – are not in the middle of the button.
What can I do?
I recommend calling setText() from inside increment and decrement instead of touching the variable value. Have a unified place where the value is changed.
Cool widget, thanx.
It would be grat to make min & max adjustable & introduce step setting to have an ability to increment/decrement for value different from 1.
Thanks Jeff, this neat little solution has been great help.
Cheers,
Rob